Salford Predictive Modeler - программное обеспечение для решения задач машинного обучения и предсказательной аналитики
Salford Predictive Modeler (SPM) представляет собой высокоточную и быструю платформу для разработки описательных и предсказательных аналитических моделей, которая позволяет связать результаты последних научных разработок в области построения моделей и алгоритмов с практическими задачами, возникающими в ежедневной работе специалистов. SPM включает в себя несколько решателей: CART®, MARS®, TreeNet®, Random Forests®, а также дополнительный функционал для автоматизации моделирования. Спектр задач, которые пользователи могут решать с использованием SPM охватывает задачи классификации, регрессии, кластеризации и сегментации. Дополнительно существуют возможности проведения анализа выживаемости, работы с несбалансированными данными и многое другое. Инструменты автоматизации в SPM ускоряют процесс разработки, анализа и настройки моделей.
Основные возможности Salford Predictive Modeler® 8:
Если у Вас возникли дополнительные вопросы по данному продукту, мы всегда будем рады на них ответить!
Решатели SPM
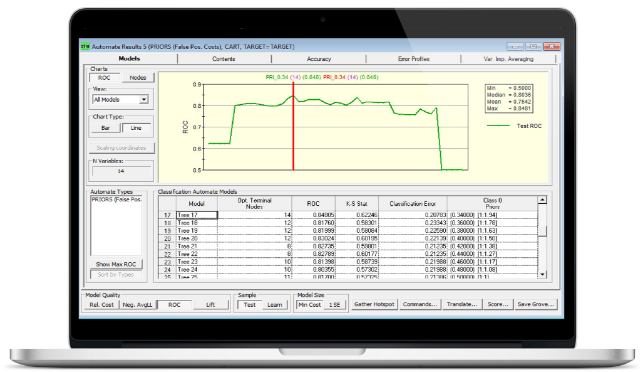
Вычислительное ядро CART® предназначено для построения деревьев решений для решения задач классификации. На сегодняшний день CART является одним из основных и часто используемых методов для извлечения данных. Использование деревьев решений позволяет быстро выявить скрытые зависимости между переменными, а графический интерфейс упрощает разработку модели и интерпретацию результатов как для подготовленных пользователей, так и для новичков. Встроенные расширения классического алгоритма CART позволяют эффективно использовать его для задач исследования рынка и web-аналитики. Оптимизированный код позволяет получать результаты в реальном времени даже работая с большими объемами данных. Алгоритм CART является не только одним из наиболее простых и популярных методов анализа, но и лежит в основе техник бустинга и бэггинга.
Методы Random Forests® основаны на исследовании нескольких альтернативных вариантов анализа, рандомизации стратегий поиска и групповом обучении. Они представляют собой набор, состоящий из большого числа различных независимых деревьев решений CART. Итоговый результат основан на суммарном ответе всего множества деревьев. К сильным сторонам метода ансамблей относятся возможности обнаружения выбросов и аномальных данных, формирование близких кластеров, идентификация наиболее важных входных переменных, обнаружение паттернов в данных, замена пропусков в данных и многое другое. Большинство методов работы с уже построенным множеством деревьев решений запатентованы и доступны только в SPM!
Вычислительное ядро MARS® предназначено для построения сплайновых регрессионных моделей, которы позволяют учесть значительную нелинейность и скрытые зависимости между переменными, недоступные для классических регрессионных моделей. Итоговая модель строится на основе множества прямых линий, каждая из которых искривлена по собственному закону. Модели, разработанные с помощью MARS®, позволяют, к примеру, прогнозировать сумму, которую клиент потратит на мобильную связь или сумму, которую посетитель потратит при следующем посещении интернет-магазина. Дополнительно предусмотрена возможность решения бинарных задач классификации.
Методы градиентного бустинга — это наиболее гибкие и мощные инструменты для извлечения данных, которые способны генерировать точные модели на постоянной основе. Точность моделей, построенных с помощью вычислительного ядра TreeNet зачастую выше любой модели, построенной с помощью какого-либо одного метода, а также с использованием классических методов бустинга или бэггинга, как для задач регрессии, так и для задач классификации. В отличии от нейронных сетей, методы TreeNet не настолько чувствительны к ошибкам в данных, а также не требует длительной подготовки и предобработки данных и могут работать с данными, содержащими большое число пропусков. В TreeNet также предусмотрен механизм обнаружения скрытых зависимостей в данных, который выдает диагностические сообщения пользователю с рекомендациями по улучшению моделей.

